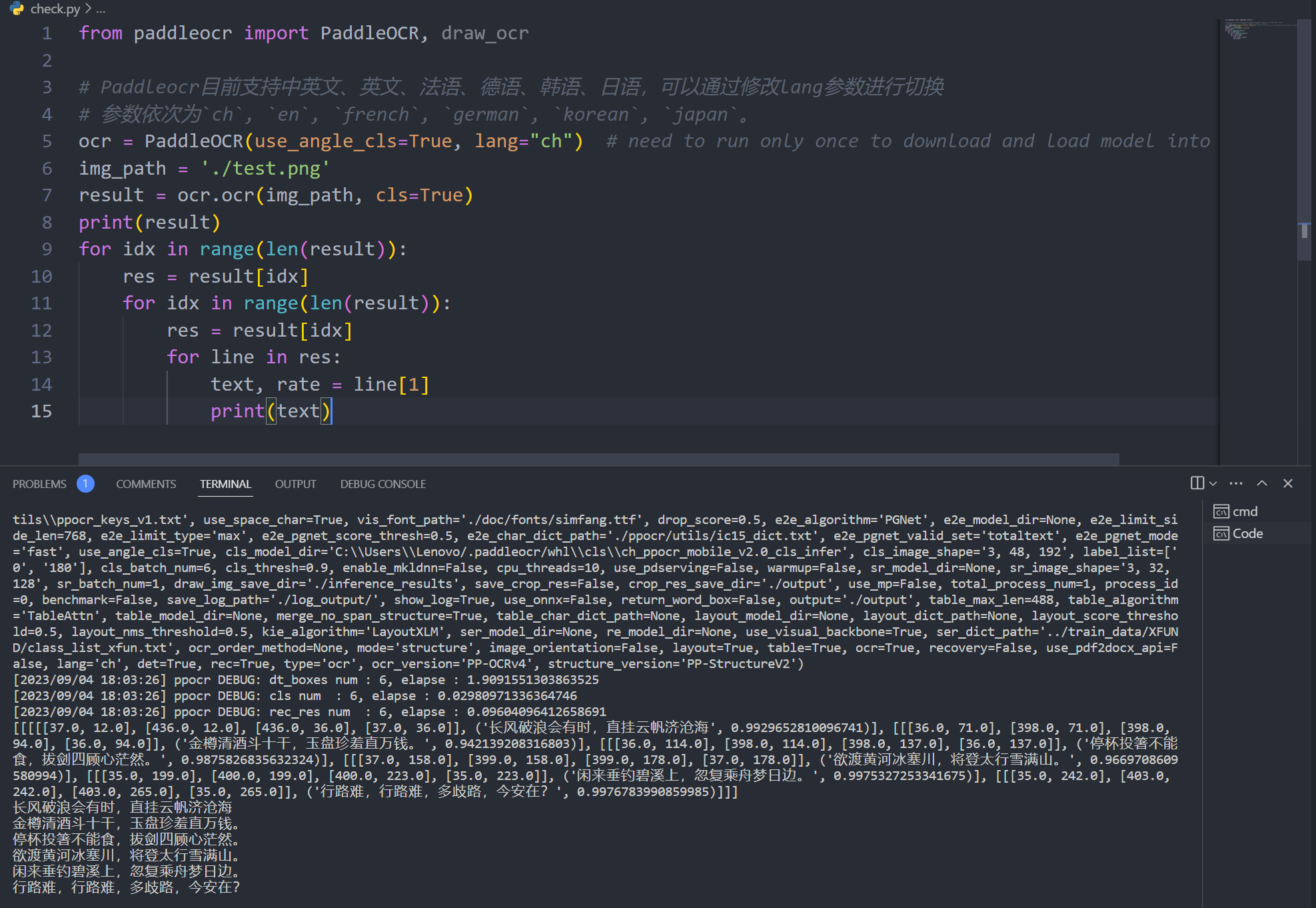
paddleocr 处理截图
最早接触 paddleocr 是去年此时,面对大量的健康码、通行码需要检查,本想通过程序实现检测,可惜最后没有完成。
本次的任务为处理青年大学习的截图数据,思考了一会还是决定继续 ocr 的方案。
主要是对图片中文字信息进行提取,然后自定义字符串的处理逻辑从而达到目标效果。
本文不是关于 OCR 原理、PaddleOCR 项目内容的介绍,仅是作为实际应用 PaddleOCR 的一个例子进行展示。
前期准备
简单概括我们要做的事情就是:
- 安装好 PaddleOCR 的相关依赖
- 安装 CUDA、cuDNN
- 安装 Paddle
- 安装 PaddleOCR whl 包
- 编写 Python 脚本并调用 PaddleOCR 进行处理
实际上非常简单。
在此之前还需要掌握 Python 的基础语法。
关于 PaddleOCR
PaddleOCR 是基于 Paddle 的一个 OCR 项目,具体介绍可以参阅下面链接:
PaddleOCR – Github
PaddleOCR – Gitee
PaddlePaddle 支持使用 GPU 和 CPU 两种,如果电脑有英伟达的独立显卡,则推荐使用 GPU 版本。此处均以 GPU 版进行介绍。
环境信息
| 版本 | |
|---|---|
| 操作系统 | Windows 11 |
| Python 版本 | 3.9.13 |
| CPU | AMD Ryzen 7 5800H |
| GPU | RTX 3050 Ti Laptop 4G |
开始配置 PaddleOCR
具体的流程也可以参阅 PaddleOCR 快速开始 – Gitee
安装 CUDA、cuDNN
使用 GPU 版本的 Paddle 必须要安装 CUDA 和 cuDNN。
流程:
- 确定本机可以安装的 CUDA 版本
- 下载对应的 CUDA
- 选择与 CUDA 对应的 cuDNN 版本
- 遇到的问题总结
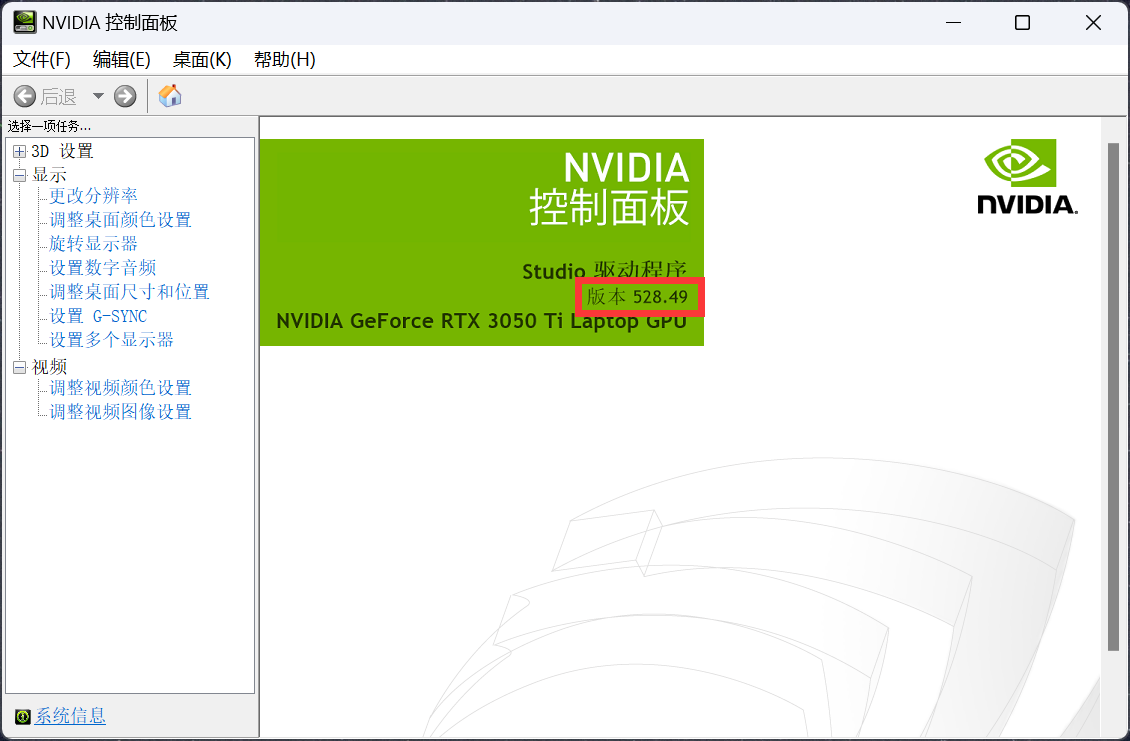
确定本机可以安装的 CUDA 版本:
CUDA 版本是与显卡驱动相关的,通过 NVIDIA 控制面板我们可以查看到自己的驱动版本(通常在桌面右键 – 显示更多选项 – NVIDIA 控制面板就可以找到)。
根据驱动版本可以在官方说明中找到对应的 CUDA 版本。
官方说明:
NVIDIA CUDA Toolkit Release Notes
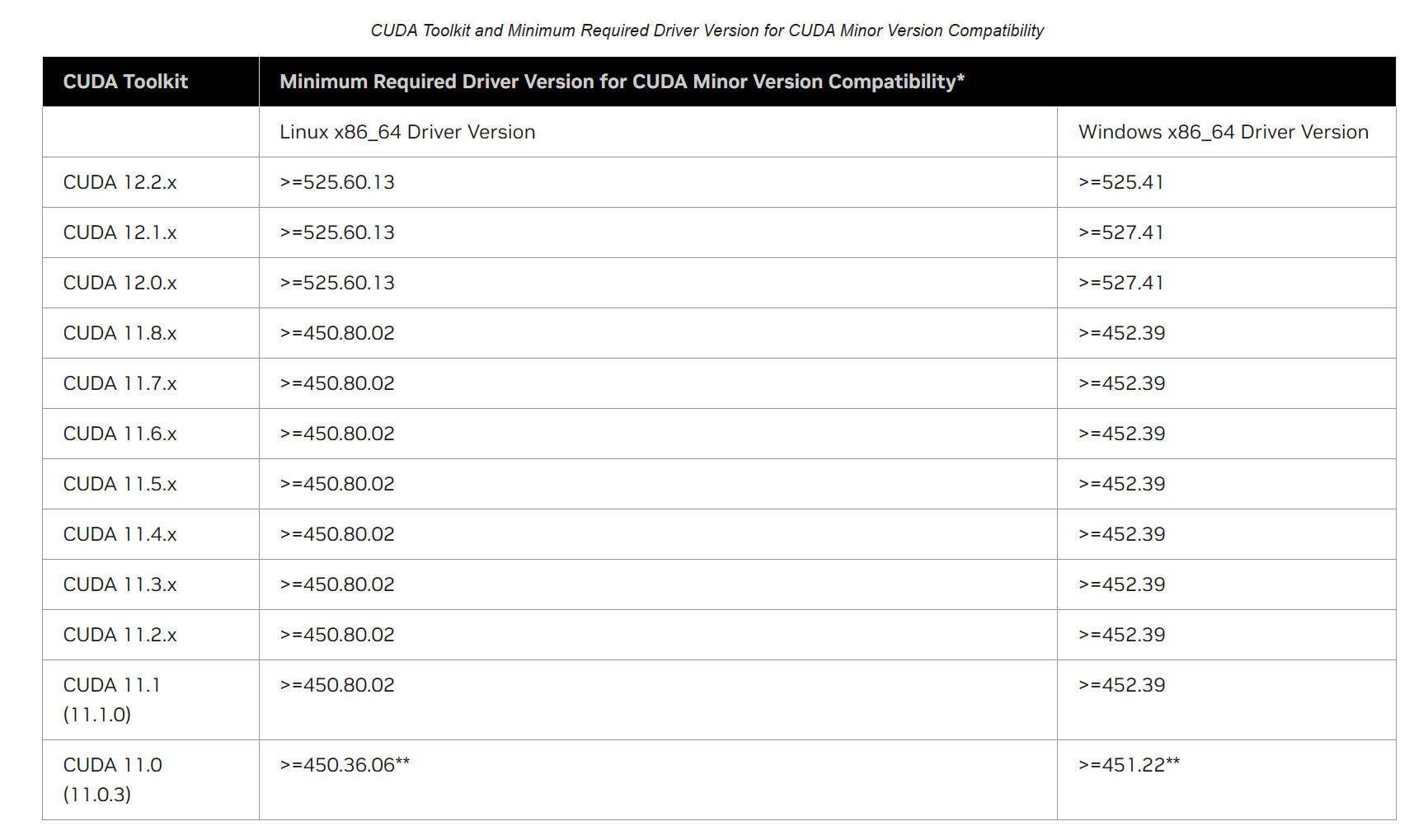
下载并安装 CUDA:
直接打开官网下载即可:
CUDA Toolkit Archive
下载好后点击安装,没有特殊需要所有选项默认即可:
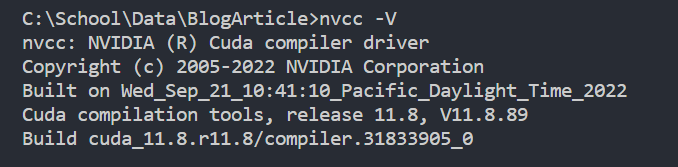
安装好后在命令终端中输入 nvcc -V 查看版本:
下载并安装 cuDNN:
首先根据 CUDA 版本确定我们需要的 cuDNN:
cuDNN Archive
下载 cuDNN 需要注册一个账号,正常注册并登录后就能下载了。
下载的结果是一个压缩包,其中包含至少三个文件夹:
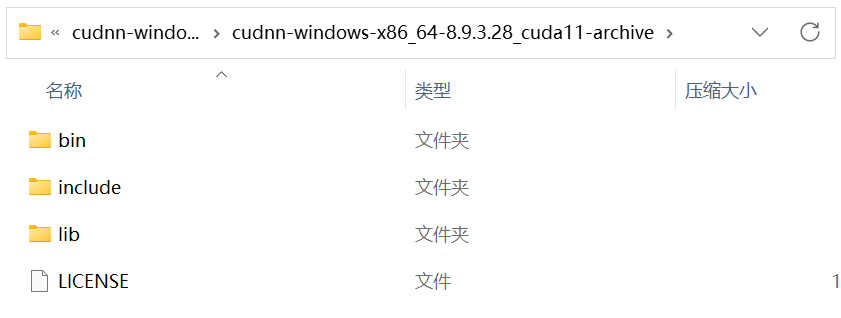
我们将压缩包中的所有文件复制到 CUDA 的安装目录,如果使用的默认选项,目录则为C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8。
最后一级目录为 CUDA 版本号,如果安装了多个 CUDA 版本,请注意区分。
复制完成后就告一段落了。
问题总结:
在运行 Python 脚本时提示了一些错误:
- cuDNN 缺失
RuntimeError: (PreconditionNotMet) The third-party dynamic library (cudnn64_8.dll) that Paddle depends on is not configured correctly.
该报错是 cuDNN 没有安装导致的,正常安装好后就没问题了。
- zlib.dll 缺失
Could not locate zlibwapi.dll. Please make sure it is in your library path
在 C:\Windows\System32 目录下缺少 zlib.dll。
zlib.dll 下载地址
注意,下载页面中有 32 位和 64 位的两种版本,通常选择 64 位的版本。
下载完成后在压缩包中找到 zlibwapi.dll 并复制到 C:\Windows\System32 目录下即可。
如果下载了错误的版本则会导致下面的第三个错误。
- zlib.dll 版本错误
Could not load library zlibwapi.dll. Error code 193. Please verify that the library is built correctly for your processor architecture (32-bit, 64-bit)
下载正确版本的 zlib.dll 就可以了。
完成以上步骤 就可以准备安装 Paddle 了。
安装 Paddle 及 paddleocr
安装 paddle:
安装 Paddle 需要先安装 Python,可以使用 Anaconda 管理 Python,这里不再详述,只关注安装 Paddle。
我们可以在官网获取 Paddle 的安装命令:
Paddle 安装
此处为 CUDA 11.8 版本的命令,其他版本可以在上述链接获取。
pip install paddlepaddle-gpu==2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完毕后可以用解释器验证一下:
import paddle
paddle.utils.run_check()

安装 paddleocr:
可以直接使用 pip 进行安装
pip install paddleocr
问题总结:
在安装 whl 包时可能有些依赖下载失败并报错:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. conda-repo-cli 1.0.20 requires clyent==1.2.1, but you have clyent 1.2.2 which is incompatible. conda-repo-cli 1.0.20 requires nbformat==5.4.0, but you have nbformat 5.5.0 which is incompatible.
类似的错误我们只需要使用 pip 单独安装其中的依赖即可,如:
pip install clyent==1.2.1
pip install nbformat==5.4.0
至此,paddleocr 安装完成
使用 paddleocr
paddleocr 的使用非常简单,官方文档具体可以参阅:
paddleocr whl – Gitee
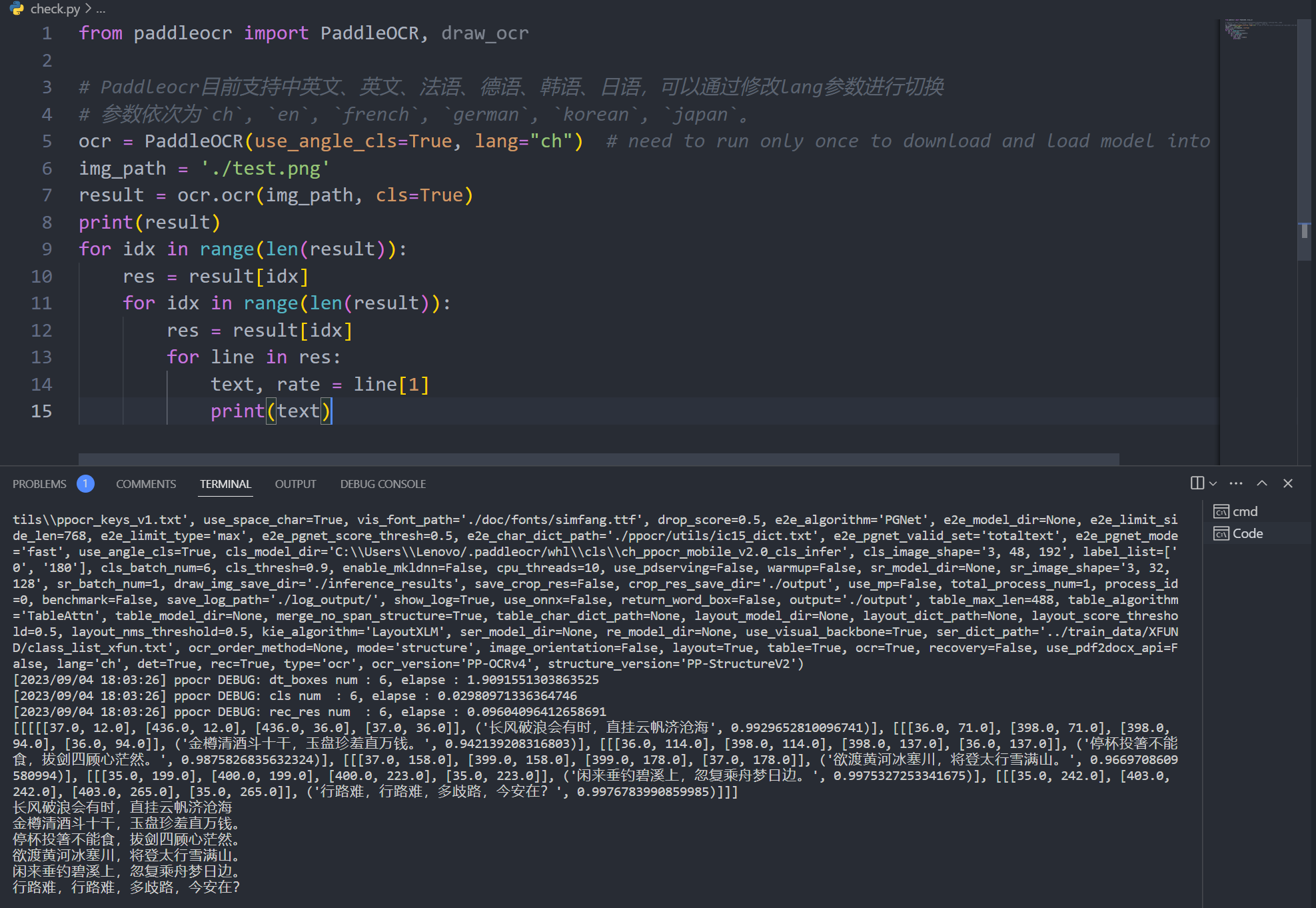
以下是文档中的官方示例:
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换
# 参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`。
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = 'PaddleOCR/doc/imgs/11.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
官方示例中还包含了识别结果的可视化,这里暂时省略。
初次使用 paddleocr 时会自动下载ppocr轻量级模型作为默认模型,可以根据上述官方文档中的介绍进行自定义更换。
ocr 识别的结果是一个list,每个item包含了文本框,文字和识别置信度
[
[
[
[
[37.0, 12.0],
[436.0, 12.0],
[436.0, 36.0],
[37.0, 36.0]
],
('长风破浪会有时,直挂云帆济沧海', 0.9929652810096741)
],
[
[[36.0, 71.0], [398.0, 71.0], [398.0, 94.0], [36.0, 94.0]],
('金樽清酒斗十干,玉盘珍羞直万钱。', 0.942139208316803)
],
[
[[36.0, 114.0], [398.0, 114.0], [398.0, 137.0], [36.0, 137.0]],
('停杯投箸不能食,拔剑四顾心茫然。', 0.9875826835632324)
],
[
[[37.0, 158.0], [399.0, 158.0], [399.0, 178.0], [37.0, 178.0]],
('欲渡黄河冰塞川,将登太行雪满山。', 0.9669708609580994)
],
[
[[35.0, 199.0], [400.0, 199.0], [400.0, 223.0], [35.0, 223.0]],
('闲来垂钓碧溪上,忽复乘舟梦日边。', 0.9975327253341675)
],
[
[[35.0, 242.0], [403.0, 242.0], [403.0, 265.0], [35.0, 265.0]],
('行路难,行路难,多歧路,今安在?', 0.9976783990859985)
]
]
]
如果只关注识别的文字结果,可以这样进行处理:
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
text, rate = line[1] #通过解包获取到 识别的文本

数据处理
通过上面的处理,我们已经可以拿到所有的图片上的文字信息,最简单的方式就是直接匹配字符串:
import pandas as pd
from paddleocr import PaddleOCR, draw_ocr
import os
learnList = {} # 一个 dict,key 是姓名,value 是学了哪几期
videoList = {'第1期', '第2期', '第3期', '第4期', '第5期', '第6期', '第7期', '第8期', '第9期', '第10期',
'第11期', '第12期', '第13期', '第14期', '第15期', '辑', '辑', '第18期'} # 预处理一下所有的视频标号
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
def checkVideo(text):
result = ""
for i in videoList:
if(text.find(i) != -1):
result = i
return result
return "nothing"
def getText(studentName, imgPath):
img_path = imgPath
result = ocr.ocr(img_path, cls=True)
print(result)
for idx in range(len(result)):
res = result[idx]
for line in res:
text, rate = line[1]
temp = checkVideo(text)
if(temp != "nothing"):
if(temp == "辑"):
learnList[studentName].append("特辑")
elif(studentName in learnList):
if(temp not in learnList[studentName]):
learnList[studentName].append(temp)
else:
learnList[studentName] = [temp]
dirList = os.listdir('./')
for i in dirList:
if(i.find(".jpg") != -1):
studentName = i.split('.')[0]
print(studentName)
getText(studentName, "./"+i)
max_len = max(len(v) for v in learnList.values())
# 填充不足的部分
for key in learnList:
learnList[key] += [''] * (max_len - len(learnList[key]))
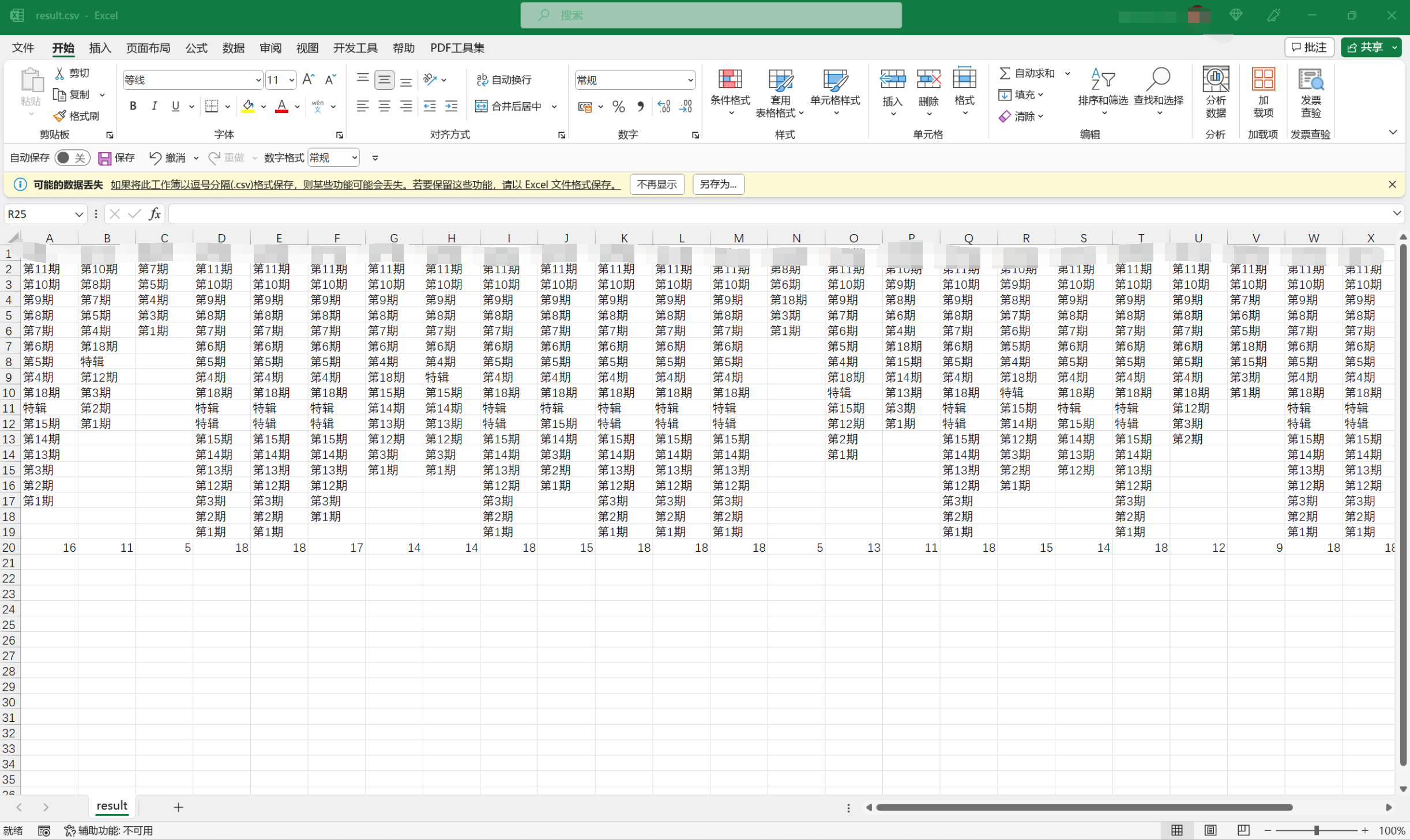
result = pd.DataFrame(learnList)
result.to_csv('result.csv', index=None, encoding="utf-8-sig")

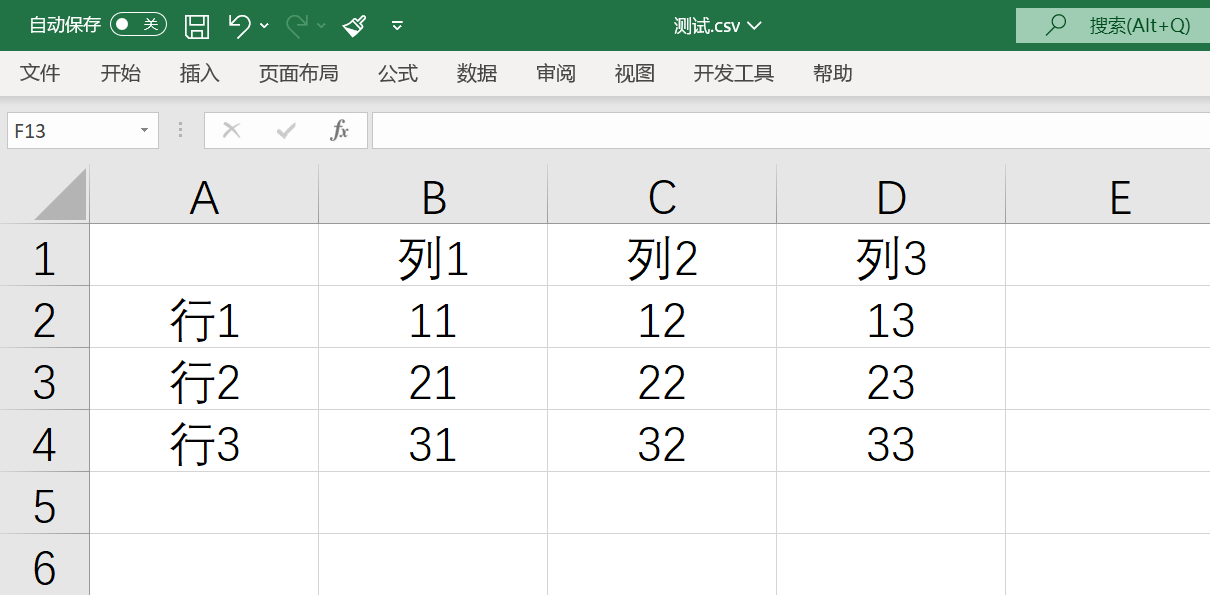
最终的结果被保存在一个 csv 文件中。(关于 csv 文件的读写可以参阅 CSV 文件的读写)
后记
除去实操前的构思(拖延),一共花了 5 个小时,大部分时间都浪费在了安装 CUDA 上,最后一算账,还不如手数来的快QAQ
但是写本篇博客的时候重走一遍这个流程就变得十分的顺畅了,或许以后还有类似的处理任务(如果是一年前就可以处理健康码了),只能安慰自己说改起来更方便了吧T_T




你说用来数学习强国多好!